Zero-Shot and Few-Shot Video Question Answering with Multi-Modal Prompts
-
Abstract
Recent vision-language models are driven by large-scale pretrained models. However, adapting pretrained models on limited data presents challenges such as overfitting, catastrophic forgetting, and the cross-modal gap between vision and language. We introduce a parameter-efficient method to address these challenges, combining multimodal prompt learning and a transformer-based mapping network, while keeping the pretrained models frozen. Our experiments on several video question answering benchmarks demonstrate the superiority of our approach in terms of performance and parameter efficiency on both zero-shot and few-shot settings.
Method Overview
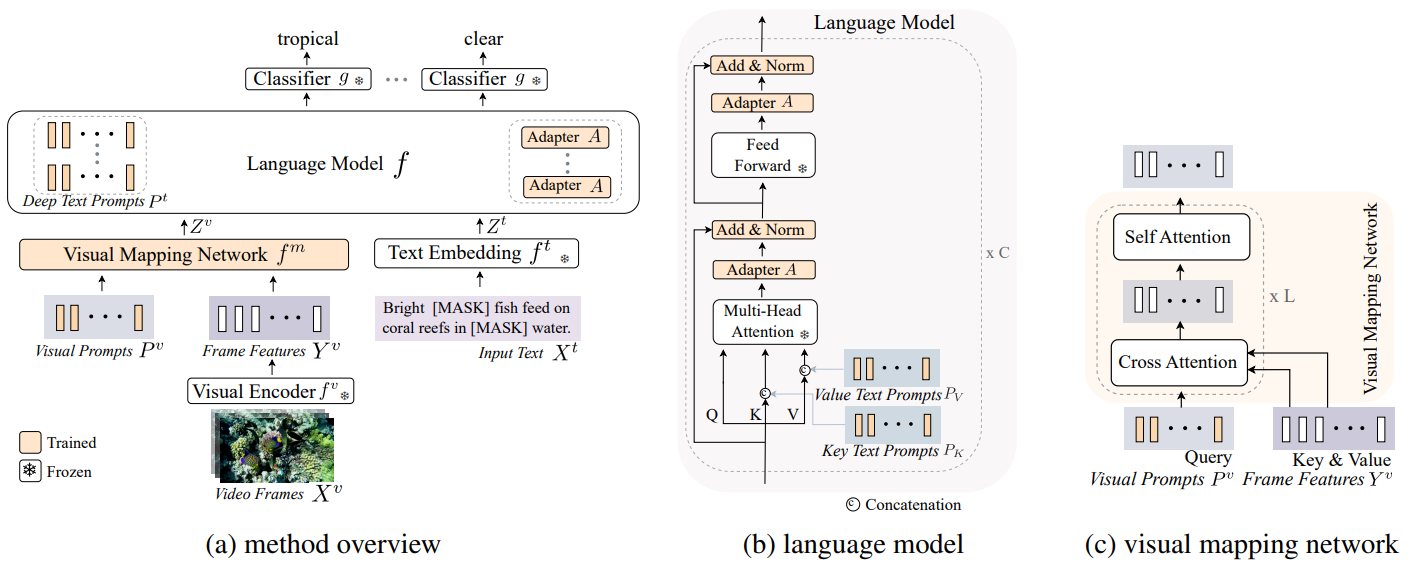
(a) ViTiS consists of a frozen video encoder, a visual mapping network, a frozen text embedding layer, a frozen language model and a frozen classifier head. Given input video frames and text, video encoder extracts frame features and the visual mapping network maps them to the same space as the text embeddings obtained by text embedding layer. Then, the language model takes the video and text embeddings as input and predicts the masked input tokens. (b) The language model incorporates learnable text prompts in the key and value of multi-head-attention and adapter layers after each self-attention and feed-forward layer, before LayerNorm. (c) Our visual mapping network consists of a number of layers, each performing cross-attention between learnable visual prompts and video frame features followed by self-attention.
-
Citation
@inproceedings{engin_2023_ICCV, title={Zero-Shot and Few-Shot Video Question Answering with Multi-Modal Prompts}, author={Engin, Deniz and Avrithis, Yannis}, booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops}, year={2023} }
-
Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation 2022-AD011012263R2 made by GENCI.