On the hidden treasure of dialog in video question answering
-
Abstract
High-level understanding of stories in video such as movies and TV shows from raw data is extremely challenging. Modern video question answering (VideoQA) systems often use additional human-made sources like plot synopses, scripts, video descriptions or knowledge bases. In this work, we present a new approach to understand the whole story without such external sources. The secret lies in the dialog: unlike any prior work, we treat dialog as a noisy source to be converted into text description via dialog summarization, much like recent methods treat video. The input of each modality is encoded by transformers independently, and a simple fusion method combines all modalities, using soft temporal attention for localization over long inputs. Our model outperforms the state of the art on the KnowIT VQA dataset by a large margin, without using question-specific human annotation or human-made plot summaries. It even outperforms human evaluators who have never watched any whole episode before.
Method Overview
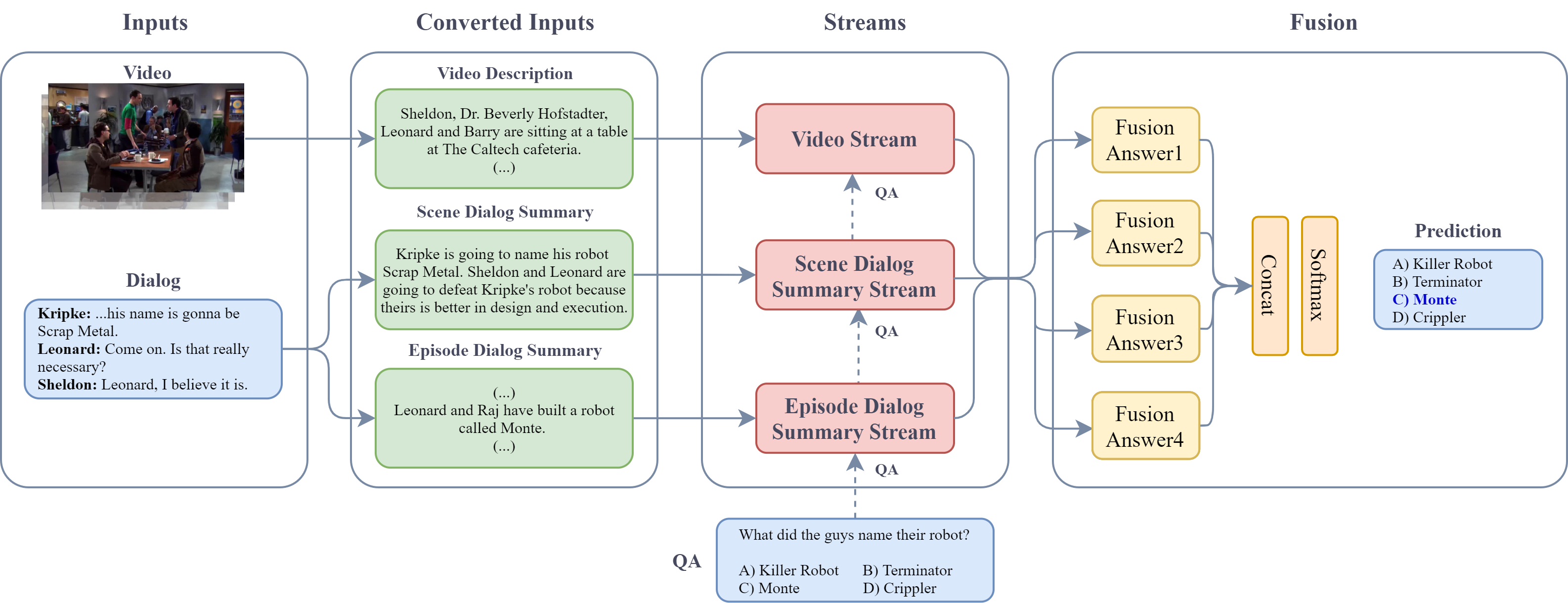
Our VideoQA system converts dialog and video inputs to episode dialog summaries and video descriptions, respectively. Converted inputs and dialog are processed independently in streams, along with the question and each answer, producing a score per answer. Finally, stream embeddings are fused separately per answer and a prediction is made.
-
Citation
@inproceedings{engin2021hidden, title={On the hidden treasure of dialog in video question answering}, author={Engin, Deniz and Schnitzler, Fran{\c{c}}ois and Duong, Ngoc QK and Avrithis, Yannis}, booktitle={ICCV}, year={2021} }
-
Acknowledgements
This work was supported by the European Commission under European Horizon 2020 Programme, grant number 951911 - AI4Media. This work was granted access to the HPC resources of IDRIS under the allocation 2020-AD01101226 3 made by GENCI.